WDF*IDF demystifiziert - Termgewichtung für Nichtmathematiker
Warum WDF*IDF eigentlich gar nicht so kompliziert ist und warum es trotz aller Unkenrufe nützlich für Onpage-SEO sein kann
Inhaltsverzeichnis
Über die WDF*IDF-Formel wurde in den vergangenen Jahren viel geschrieben und diskutiert. Nachdem die Suchmaschine Google viel stärker gegen künstlichen Linkaufbau vorgegangen ist, schien es logisch, den Fokus bei der Suchmaschinenoptimierung nun wieder verstärkt auf gute Onpage-Optimierung zu legen. Da kam eine „Zauberformel“ wie WDF*IDF gerade recht – versprach sie doch scheinbar tolle Rankings ohne großartigen Linkaufbau.
Auffällig bei vielen Diskussionen in der SEO-Szene war, dass viele das Konzept hinter WDF*IDF offenbar nicht richtig verstanden haben. Die Frage „Funktioniert WDF*IDF?“ brachte viele kontrovers diskutierte Standpunkte hervor. Das ging von mathematisch fundierten Analysen bis Stammtischparolen-ähnlichen Ausrufen wie „Ich schreibe tollen Content für den Leser, dann rankt das auch automatisch gut bei Google!“.

Man muss kein Einstein sein, um die Idee hinter WDF*IDF zu verstehen.
Welche Faktoren beeinflussen das Ranking?
Landauf landab werden viele verschiedene Faktoren diskutiert, die möglicherweise einen Einfluss auf das Google-Ranking haben. Niemand kann mit letzter Bestimmtheit sagen, welchen Einfluss ein gewisser Faktor auf das Ranking hat – lassen Sie sich daher keine absoluten Aussagen andrehen. Keyword-Dichte spielt keine Rolle und der Pagerank ist unwichtig? Wie kann jemand, der keinen Einblick in den Google-Algorithmus hat, eigentlich so etwas mit letzter Bestimmtheit sagen? Man kann nun diese scheinbar populären Thesen einfach nachplappern. Oder aber, man versucht, die dahinterstehenden Konzepte erstmal zu verstehen. Danach kann man dann selbst entscheiden, ob man es für sinnvoll hält, wenn ein Faktor beim Ranking eine Rolle spielt oder nicht. Letztendlich bleibt auch das dann nur Mutmaßung – aber abgesehen von konkreten Experimenten (die natürlich auch immer fehlerbehaftet sein können) ist das immer noch die beste Vorgehensweise.
Um zurück zum Thema WDF*IDF zu kommen: Inwiefern eine Optimierung der Termgewichtung nach WDF*IDF einen positiven Einfluss auf das Ranking hat, kann niemand mit Sicherheit sagen. Sinnvoll wäre es daher, das dahinter stehende Konzept zu verstehen und dann selbst zu entscheiden, ob man eine solche Optimierung für nützlich hält.
Viele Abhandlungen wurden über das Thema geschrieben, meist wird dabei intensiv die mathematische Formel von WDF*IDF diskutiert und erklärt. Das Problem mit mathematischen Formeln ist: sehr viele Menschen stehen mit der Mathematik mehr oder weniger auf Kriegsfuß und sobald komplizierte Formeln ins Spiel kommen, schalten sie innerlich ab. Ein Text, der WDF*IDF fachlich sachlich mathematisch erläutert wird sich daher vermutlich schwer damit tun, den vielen Nichtmathematikern das Thema adäquat zu erklären.
Die gute Nachricht ist jedoch: als Anwender ist die mathematische Formel für Sie eigentlich gar nicht von Interesse. Entscheidend ist viel mehr das Konzept, die Idee, die dahinter steht. Um diese zu verstehen brauchen Sie sich nicht unbedingt mit den mathematischen Details zu befassen. Dieser Artikel wird daher darauf verzichten, Sie mit komplexen mathematischen Formeln und Berechnungen zu verwirren, sondern versuchen, Ihnen die Grundidee hinter WDF*IDF und den entsprechenden Analysetools näher zu bringen.
Am Anfang war: die Relevanz
Doch beginnen wir ganz am Anfang, noch weit entfernt von WDF*IDF und ähnlichem. Worum geht es überhaupt? Das Ziel ist es, Relevanz innerhalb von Texten zu messen. Die Aufgabenstellung lautet also: wenn ich einen Text habe und einen Begriff (der in diesem Text vorkommen kann oder auch nicht), wie messe ich dann die Relevanz, die dieser Begriff innerhalb des Textes besitzt?
Ein erster Ansatz ist dabei die weithin bekannte Keyworddichte: dabei wird dann die Anzahl der Vorkommen des Terms durch die Gesamtanzahl der Wörter im Text geteilt. Bei einem Text, der aus 300 Wörtern besteht und in dem 9 mal der Term „Waschmaschine“ vorkommt wäre die nach der Keyworddichte berechnete Relevanz des Termes „Waschmaschine“ also 9 / 300 = 0,03 bzw. 3 %.
Die Keyworddichte als Maß zur Messung der Relevanz hat einige unübersehbare Vorteile: sie ist einfach zu berechnen und sie ist intuitiv. Wer gesagt bekommt, dass er einen Text mit einer Dichte von 3 % schreiben soll, der weiß, dass demnach im Schnitt ca. jedes dreißigste Wort das Hauptkeyword sein soll.
Der Wert ist einfach zu berechnen – und hat damit in der Praxis natürlich auch einige Nachteile. Das erste Problem ist: der Relevanzwert steigt linear mit der Anzahl des Terms an. Wenn man einen Term also doppelt so oft verwendet, verdoppelt sich auch die Keyworddichte. Verzehnfacht man den Term – verzehnfacht sich auch der Relevanzwert.
In der Praxis ist das aber eher ungünstig: je öfter man einen Term in einem Dokument verwendet, desto relevanter wird der Term zwar. Wenn ein Term aber schon oft in einem Text enthalten ist und er dann noch mehrmals „reingequetscht“ wird, erhöht das die Relevanz dann wirklich noch? Um es anhand eines Beispiels darzustellen: wenn man einen Term statt 10 mal nun 20 mal verwendet, verdoppelt man die Relevanz. Nimmt man nun ein Dokument, indem der Term dagegen schon 100 mal vorkommt und fügt den Term dort nun noch 100 mal ein, sodass er 200 mal enthalten ist, hat man bezüglich der Keyworddichte die Relevanz ebenfalls verdoppelt. Aber sollte der „Relevanzsprung“ im ersten Fall nicht größer sein, als im zweiten? Wenn ein Keyword noch nicht so oft im Text vorhanden ist, sollte sich das Hinzufügen doch deutlicher auf die Relevanz auswirken, als wenn das Keyword sowieso schon sehr oft im Dokument vorkommt.
So ähnlich wird das auch bei Google gehandhabt, wie Matt Cutts in diesem Video ab Sekunde 43 erklärt: wenn ein Wort zum ersten Mal im Dokument auftaucht, steigt die Relevanz sprunghaft an. Auch beim zweiten Mal macht die Relevanz noch einen kleinen Sprung, jedoch einen kleineren als zuvor. Bei jedem weiteren Vorkommen des Terms steigt die Relevanz dann ein bisschen weniger an als beim vorherigen, bis dann irgendwann das Hinzufügen des Terms so gut wie keine messbare Verbesserung der Relevanz mehr mit sich bringt.
Within-Document-Frequency (WDF)
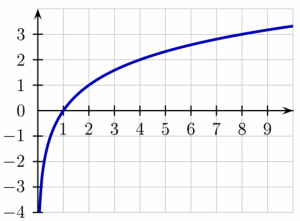
Der Logarithmus bewirkt eine Dämpfung: die Kurve steigt zunächst sehr steil an, später dann aber nur noch schwach.
Abbildung: Wikipedia (Brona), CC BY-SA
Mathematisch abgebildet wird das durch die sogenannte Within-Document-Frequency, abgekürzt WDF. Statt einfach die Häufigkeit des Keywords durch die Gesamtanzahl der Wörter im Text zu teilen, wie das bei der Keyworddichte der Fall ist, werden beim WDF die beiden Werte (also Termfrequenz und Länge des Textes) noch logarithmiert. Der Logarithmus bewirkt dabei die zuvor besprochene Dämpfung: beim ersten Auftreten eines Terms steigt die Relevanz stärker an als bei den weiteren Vorkommen desselben Terms in dem Dokument.
Ersetzen wir die gewöhnliche Density also durch die beschriebene WDF, erhalten wir ein besser geeignetes Maß zur Messung von Relevanz in Texten. Dennoch hat auch dieses Maß noch manche Schwächen. Wir wollen uns das anhand eines konkreten Beispiels ansehen. Betrachten Sie dazu den folgenden Text.
Im Sommer arbeite ich gerne im Garten. Dort wachsen viele schöne Blumen, die mein Nachbar nicht in seinem Garten findet.
Aus diesem kurzen Text picken wir uns jetzt zwei Ausdrücke heraus: „Garten“ und „im“. Beide Begriffe kommen genau zweimal im Text vor, nach der Wikipedia-Formel für die WDF errechnet sich für beide demnach ein Relevanzwert von 0,36. Will heißen: glaubt man der WDF, sind diese beiden Terme gleich relevant innerhalb des gezeigten Textabschnittes. Intuitiv würde man dagegen vermuten, dass der Begriff „Garten“ für den Text deutlich relevanter ist als „im“.
Das Problem der WDF ist also: jedes Wort wird gleich bewertet. Tauchen zwei Begriffe gleich oft in einem Dokument auf, wird ihre Relevanz auch als gleich bewertet. Es wäre daher sinnvoll, auch die Terme selbst noch in irgend einer Form zu bewerten und das in die Berechnung mit einfließen zu lassen.
Inverse-Document-Frequency (IDF)
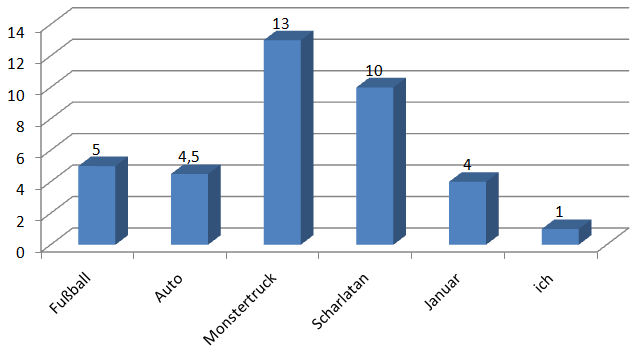
Beispiele für IDF-Werte: je geläufiger ein Begriff, desto kleiner der IDF-Wert
Zuvor hatten wir geschrieben: intuitiv würden wir in dem Beispieltext das Keyword „Garten“ als relevanter bewerten als „im“. Doch warum ist das so, wo doch beide Wörter gleich oft im Text vorkommen? Nun, „im“ ist ein viel generelleres Wort als „Garten“. „im“ kann in sehr vielen unterschiedlichen Texten verwendet werden, während „Garten“ sehr viel spezieller ist. Verallgemeinert könnte man also sagen, je spezieller ein Wort ist, desto relevanter ist es für den Text, in dem es vorkommt.
Ein paar Beispiele gefällig? „Thorsten“ ist spezieller als „ich“. „Lenkrad“ ist spezieller als „Auto“. „Dachgiebel“ ist spezieller als „Haus“. Würden die genannten Keywords in einem Text jeweils gleich oft vorkommen, sollten das jeweils speziellere bei einer Relevanzmessung besser abschneiden.
Doch wie wird so etwas in der Praxis realisiert? Wie kann man Ausdrücke hinsichtlich ihres Spezialitätsgrades bewerten? Die Lösung hierfür heißt Inverse-Document-Frequency, kurz IDF. Bei der IDF erhalten die Terme eine Gewichtung gemäß ihres Vorkommens in einem gesamten Dokumentenkorpus. Man betrachtet also nicht mehr bloß ein Dokument, sondern alle. Je mehr Dokumente einen Term enthalten, desto allgemeiner ist er, desto kleiner ist der IDF-Wert. Denken Sie an unseren Beispieltext von vorhin: „im“ werden Sie in fast jedem längeren deutschen Text finden, „Garten“ dagegen nur in recht speziellen Texten, die etwas mit diesem Thema zu tun haben. Der IDF-Wert von „Garten“ ist damit deutlich höher als der von „im“, weil „Garten“ ein speziellerer Term ist als „im“.
IDF bedeutet also, dass seltene Begriffe höher gewichtet werden als häufige Begriffe. Macht das denn Sinn? Mit einer kleinen Metapher soll das kurz verdeutlicht werden. Stellen Sie sich vor, Sie haben zwei gute Freunde, die Sie beide gleich gut leiden können. Natürlich freuen Sie sich jedes Mal, wenn Sie einen von den beiden sehen. Der eine besucht Sie jede Woche einmal, während der andere weiter entfernt wohnt und Sie ihn nur einmal im Jahr zu Gesicht bekommen. Obwohl Sie beide gleich gut leiden können, werden Sie sich vermutlich bei dem, den Sie sehr viel seltener sehen, ein bisschen mehr freuen, wenn Sie ihn wiedersehen.
Ebenso ist es auch mit den Termen: je seltener einer vorkommt, desto höher ist seine Gewichtung.
WDF * IDF
Bei WDF*IDF werden demnach also WDF und IDF kombiniert: zunächst wird die Within-Document-Frequency eines Terms innerhalb eines Dokumentes bestimmt. Wenn mehrere Wörter gleich oft im Text vorkommen, stimmt deren Wert bis hierhin noch überein. Danach wird das Ergebnis jedoch noch mit dem IDF-Wert für den jeweiligen Term multipliziert – damit können Keywords, die gleich oft im Text vorkommen, letztendlich einen unterschiedlichen Relevanzwert erhalten.
Die IDF ist also ein termspezifischer Wert: sie wird für jedes Wort nur einmal berechnet und dann in allen Dokumenten, in denen der Term vorkommt, so verwendet. Zuvor sprachen wir dabei von einem „Dokumentenkorpus“ und dass in „allen Dokumenten“ nach einem Term geschaut wird. Doch was ist damit konkret gemeint?
Bestimmung der IDF
Wenn wir davon ausgehen, dass auch Google bzw. Suchmaschinen generell einen ähnlichen Ansatz für die Relevanzberechnung wählen, ist es relativ einfach zu verstehen, wie die IDF-Berechnung dort funktioniert. Eine Suchmaschine hat naturgemäß einen großen Index mit allen möglichen Dokumenten aus dem Internet. Das wäre dann in dem Fall der Dokumentenkorpus. Die Suchmaschine kann also einen recht genauen IDF-Wert ermitteln, da sie für einen Term genau bestimmen kann, in wievielen Dokumenten im Index er vorkommt.
Außerhalb von Suchmaschinen hat aber niemand einen auch nur annähernd so großen Index. Alle IDF-Werte, die in Tools für die Termgewichtung verwendet werden, können demnach naturgemäß nur Näherungswerte sein. Jedes Tool verwendet dabei meist einen anderen Ansatz, daher können sich die Werte durchaus auch deutlich unterscheiden. Grundsätzlich ist das nicht weiter schlimm, so lange die Grundidee, die hinter IDF steckt, beibehalten wird: in der Sprache häufig verwendete Terme werden abgewertet, in der Sprache selten verwendete Terme werden aufgewertet.
Ungeeignete Ansätze zur IDF-Berechnung
Es sei aber an dieser Stelle darauf hingewiesen, dass es auch eher ungeeignete Ansätze zur Bestimmung der IDF gibt (die möglicherweise auch in manchen SEO-Tools für die Termgewichtung verwendet werden). Bei der IDF-Berechnung wird gezählt, in wie vielen Dokumenten ein Term vorkommt und das dann in Relation zur Gesamtanzahl der Dokumente gesetzt. Da bei der Analyse der Termgewichtung sowieso schon einige Dokumente analysiert werden, mag es auf den ersten Blick nahe liegen, diese Dokumente dann auch für die Berechnung der IDF heranzuziehen.
Tatsächlich ist das aber keine so gute Idee. Warum? Gehen wir das einmal an einem Beispiel durch. Wir möchten eine Termgewichtungsanalyse für den Suchbegriff „Zylinderkopfdichtung“ erstellen. Intuitiv würden wir davon ausgehen, dass „Zylinderkopfdichtung“ einen recht hohen IDF-Wert besitzt, weil es ein sehr spezieller Begriff ist. Wenn wir die Analyse durchführen, werden dann die TOP 10 oder TOP 20 der Google Suchergebnisse für diesen Suchbegriff analysiert. Vermutlich wird in jedem der analysierten Dokumente auch der Suchbegriff „Zylinderkopfdichtung“ vorkommen, eben weil ja danach gesucht wurde. Würde die IDF-Berechnung dann auf diesen Dokumenten basieren, erhielte „Zylinderkopfdichtung“ einen sehr niedrigen Wert, was genau das Gegenteil von dem ist, was wir von einer guten IDF-Berechnung erwarten würden.
Der gezeigte Ansatz hat zwei grundlegende Probleme: Eine zu kleine Anzahl an analysierten Dokumenten und Bias (zu deutsch: Befangenheit). Der erste Punkt ist recht offensichtlich: um herauszufinden, welche Wörter oft und welche weniger oft in der Sprache vorkommen, sollte man möglichst viele Dokumente analysieren. Mit 10 oder 20 oder 30 analysierten Dokumenten kommt man da nicht weit. Bias bedeutet, dass die Auswahl der Dokumente, aus denen die IDF berechnet wird, nicht „neutral“ ist. Wenn wir wissen wollen, ob ein Ausdruck in der Sprache eher oft oder eher selten vorkommt, ist es logischerweise keine allzu gute Idee, dafür nur die Dokumente zu analysieren, die wir bei einer Suche nach diesem Ausdruck gefunden haben.
Von der Relevanz zum Onpage-Tool für die Termgewichtung
Wir haben nun verschiedene Ansätze für die Bestimmung von Relevanz innerhalb von Dokumenten gesehen. Wir haben Schwächen der Verfahren kennen gelernt und gesehen, wie man die Schwächen ausmerzen kann mit Hilfe von verbesserten Verfahren. Es sei an dieser Stelle auch einmal gesagt: WDF*IDF ist hier immer noch nicht das Ende der Fahnenstange. Sicherlich gibt es auch hierbei noch Schwächen, die eventuell mit verfeinerten Methoden behoben werden können. Zum Beispiel berücksichtigt WDF*IDF nicht, dass bei extremem Keyword-Stuffing die Relevanz eines Termes auch wieder sinken kann (siehe das oben gezeigte SEO-Video von Matt Cutts, dort erläutert er, dass das bei Google so gehandhabt wird). Für die Praxis haben wir mit WDF*IDF nun aber erstmal ein ausreichend gutes Maß für die Bestimmung von Relevanz.
Interessant wird bei den Tools dann, wofür die Daten der Analyse verwendet werden. Wenn früher ein Text gebraucht wurde, wurde dem Texter oft nur das Hauptkeyword vorgegeben und mit welcher Density dieses innerhalb des Content auftreten sollte. Dementsprechend wurde dann schlussendlich meist auch nur die Keyworddichte des Keywords gemessen und daran die „Qualität“ des Textes bemessen. Wirklich viel kann man aber mit nur einem einzelnen Wert nicht wirklich über einen Text aussagen. Stellen Sie sich folgendes Szenario vor: Sie schreiben einen Text über das Thema Weihnachten. Dieses Keyword kommt darin mit einer Dichte von 3% vor. Nun tauschen Sie einfach jedes Vorkommen von „Weihnachten“ mit „Ostern“ aus. Der resultierende Text hat dann eine Density von 3% für das Keyword „Ostern“, dennoch ist der Text vermutlich völlig unbrauchbar.
Wir dürfen also getrost davon ausgehen, dass Google zusätzliche Faktoren verwendet, um die Qualität der Texte zu bestimmen. Sinnvoll wäre es zum Beispiel, statt nur die Relevanz des Haupttermes zu messen, auch zu prüfen, inwiefern thematisch relevante Wörter in die Texte integriert wurden. Google hat natürlich durch seinen riesigen Index sehr komplexe Möglichkeiten, um thematisch relevante Begriffe zu bestimmen. Diese Möglichkeiten haben wir natürlich nicht. Tools für die Termgewichtung setzen aber an dieser Stelle an und realisieren gewissermaßen ein „Reverse-Engineering“. Wenn wir davon ausgehen, dass Google bevorzugt solche Dokumente rankt, die die thematisch relevanten Terme gut integriert haben, können wir durch Analyse der gerankten Dokumente selbst eine ungefähre Vorstellung davon erhalten, welche Terme Google als thematisch relevant ansieht.
Dabei ist zu beachten: das ist natürlich keine exakte Wissenschaft. Selbstverständlich muss nicht jedes Dokument, das gut gerankt ist, auch die wichtigsten Terme in einer guten Intensität beinhalten. Gerade Seiten mit vielen Links ranken oft auch, ohne den allerbesten Content zu haben. Wenn man die TOP-10 oder TOP-20 zu einem Suchbegriff analysiert, findet man aber meist überraschend gute Auflistungen an thematisch relevanten Termen.
Was nutzen die gewonnenen Daten?
Mit einem Tool für die Analyse der Termgewichtung lassen sich daher hilfreiche Schlüsse für die eigene Texterstellung ziehen. Natürlich sollte man versuchen, die thematisch relevanten Begriffe möglichst gut in den eigenen Text einzubauen. Tools wie Seolingo geben dabei dann auch eine Obergrenze an, die man nicht überschreiten sollte, um nicht spammy zu wirken. Über Proof-Keyword-Filter kann man die Begriffe herausfinden, die in fast jedem der gut gerankten Dokumente vorkommen. Da macht es dann auf jeden Fall Sinn, diese in den eigenen Content zu integrieren.
Ein weiterer Faktor bei der Messung der Onpage-Qualität ist sicherlich auch die Diversität: wie gut wird ein Thema mit seinen Unterthemen von einem Dokument abgedeckt? Ein Fachbegriff, der in diesem Zusammenhang oft erwähnt wird, lautet „Holismus“ bzw die Frage „Wie holistisch ist das Dokument?“. Holistisch bedeutet ganzheitlich, ganzheitlich wiederum könnte man als das Gegenteil von einseitig ansehen. Dokumente, die ein Thema also nicht nur einseitig betrachten, sondern versuchen, es von verschiedenen Seiten zu beleuchten und unterschiedliche Ansichten integrieren, haben Chancen auf ein gutes Ranking in den SERPS. Mit einem Termgewichtungstool lässt sich die Diversität von Dokumenten sehr gut erfassen. Dokumente, die viele relevante Terme integrieren, gelten als holistisch. Ablesen kann man das bei einem SEO-Tool wie Seolingo z.B. am Gewichtungsdiagramm, wo dann schön zu sehen ist, dass viele relevante Terme ins Dokument integriert wurden. Seolingo gibt die Diversität zusätzlich für alle analysierten Dokumente auch als Kennzahl aus, so können Sie auf einen Blick die verschiedenen Dokumente vergleichen.
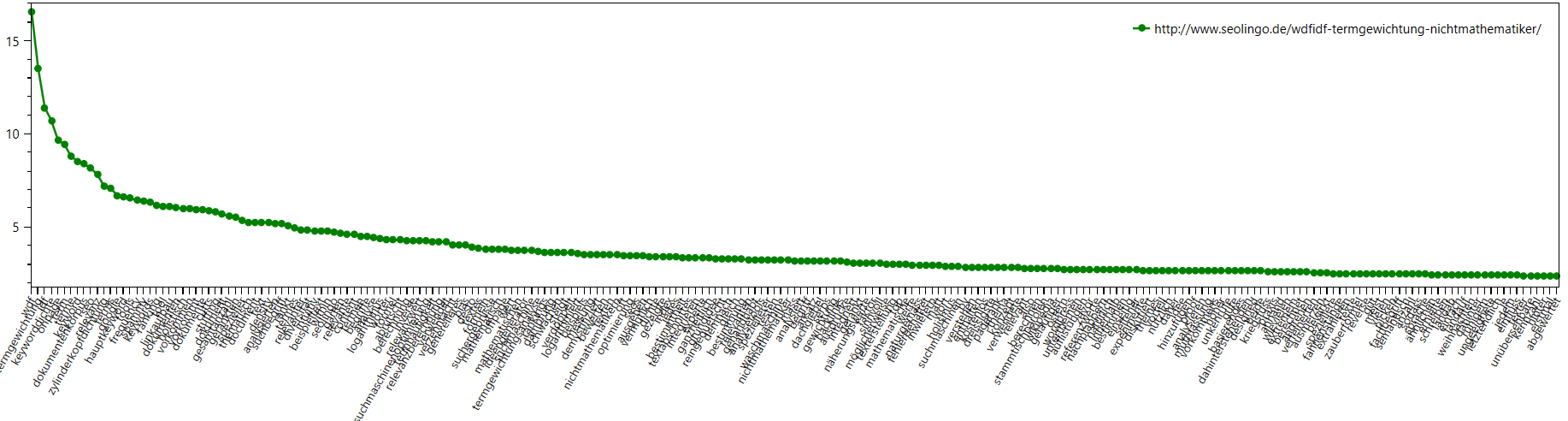
Termgewichtungskurve für dieses Dokument
Und was ist daran jetzt neu? Braucht man das überhaupt?
Von Kritikern in der SEO-Szene wurde angemerkt, dass die Formel von WDF*IDF bereits seit 1972 bekannt sei und ein darauf basierendes Tool also nicht wirklich etwas neues sein könne. Stimmt natürlich nicht so ganz. Auch wenn WDF*IDF durchaus keine neu entwickelte Formel ist, so ist die Anwendung in der Tat neu. Zumindest waren vor einigen Jahren noch keine Tools verbreitet, die eine Analyse der Suchergebnisse vorgenommen haben, um daraus semantisch relevante Terme zu extrahieren. Der Vorteil der Termgewichtungsanalyse bei der Suchmaschinenoptimierung liegt also darin, dass man ein Dokument nun nicht mehr bloß anhand eines einzelnen Keywords bewerten muss, sondern detailliert angeben kann, welche Begriffe ein Text enthalten sollte.
Die Frage, ob man ein Tool unbedingt braucht, kann man für so ziemlich jedes SEO-Tool mit ruhigem Gewissen mit nein beantworten. Das gilt sowohl für Onpage-Tools, für Offpage-Tools und auch für Ranking-Tools. Wer ein wirklicher Experte auf einem Gebiet ist, wird es vermutlich auch ohne Hilfe und ohne Tool schaffen, einen guten Text dazu zu schreiben. Möglicherweise rankt das so verfasste Dokument dann gut bei Google, möglicherweise aber auch nicht. Der Vorteil eines Tools für die Termgewichtung liegt darin, dass es zusätzliche Impulse liefern kann, an die man selbst als Experte nicht gedacht hat. Indem man für jeden Begriff Referenzwerte geliefert bekommt, kann man auch sicherstellen, dass man mit seinem Content nicht in einen „spammy“-Bereich abrutscht. Und gerade, wenn man für ein Thema kein Experte ist (was bei SEOs auch schon einmal vorkommen soll), ist es extrem hilfreich, sich via Analyse der Termgewichtung einen Überblick über das Thema verschaffen zu können.
Zusammenfassend kann man also sagen, dass WDF*IDF zwar kein völlig neues Konzept ist, die Anwendung zur Bestimmung von thematischer Relevanz aber durchaus ein Novum darstellt. Eine Analyse kann bisher nicht beachtete Themenbereiche aufzeigen und verhindern, dass man in den Bereich von Keyword-Stuffing abrutscht. Insgesamt kann die Analyse dabei helfen, deutlich bessere und intensivere Texte zu schreiben. Hierzu gab es andernorts bereits Experimente bezüglich des sogenannten Linkless-Outrankings. Dabei wurde versucht, durch Konstruktion eines optimalen Textes mittels WDF*IDF einen solchen Vorteil im Ranking zu erzielen, sodass nur noch wenige Backlinks vonnöten waren. Die konsequente Anwendung von WDF*IDF garantiert zwar keine Rankings, dennoch haben sich bei vielen dieser genannten Experimente erstaunliche Erfolge im Ranking eingestellt. Auch größer angelegte Studien haben bereits eine Korrelation zwischen der Verwendung von semantisch relevanten Termen und dem Ranking festgestellt (z.B. hier im Recap einer Searchmetrics-Studie). Natürlich führen wir auch selbst Tests durch, aktuelle Erkenntnisse können in unserer Raketenseo-Studie nachgelesen werden.
WDF*IDF Schnellcheck
Eine schnelle WDF*IDF-Analyse ist auch im SEO-Schnellcheck enthalten.
WDF*IDF kostenlos testen
Machen Sie sich selbst ein Bild von WDF*IDF und testen Sie die Onpage-Funktionen bei Seolingo kostenlos.
Im übrigen hat Seolingo noch sehr viel mehr zu bieten als nur die reine WDF*IDF-Analyse, probieren Sie es einfach aus.